
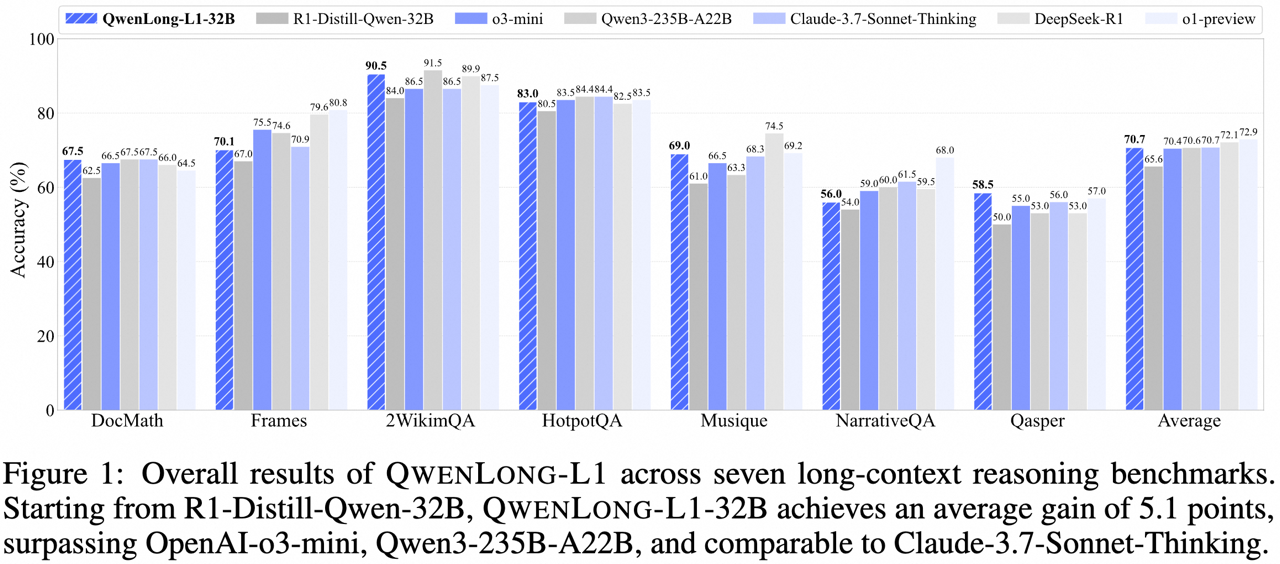
 From the huggingface repo: QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning We release 🤗 QwenLong-L1-32B, which is the first long-context LRM trained with reinforcement learning for long-context reasoning. Experiments on seven long-context DocQA benchmarks demonstrate that QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking, demonstrating leading performance among state-of-the-art LRMs. We have it on Blablador. I don’t have yet a perfect system prompt for it, so you might see some funny tokens there, like <|im_end|> and so on. In any case, it would be nice to see if it’s useful for you, and then I would keep it running. Please let me know! Let’s bark! Alex
{kind=link}